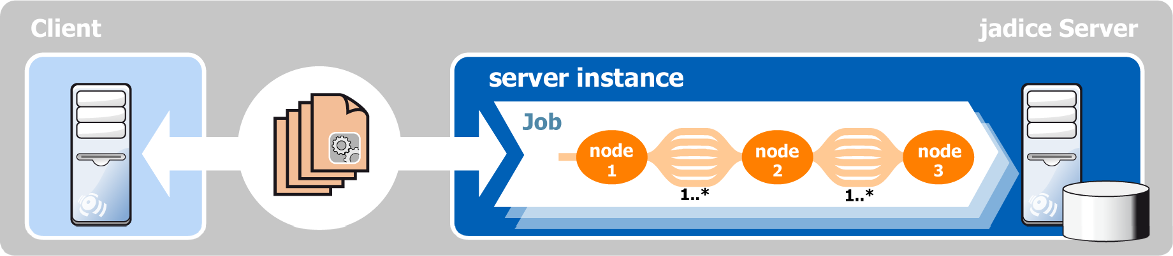
jadice server breaks processing of document data down into tasks (Jobs) and these jobs into
individual processing steps (Nodes), which thus form a workflow. Clients operate the
execution of tasks and distribute them to jadice server through the messaging system.
Nodes are the individual, delineated steps that constitute a job. They are connected to each other via bundles of data streams that carry usage data as well as meta data. Thus, the processing steps depend on the type of the job that is to be performed in regard to their content and sequence.
Nodes are distinguished by their tasks. Hence, one node might host the conversion of documents with the help of LibreOffice, MS Office or jadice document platform functionalities while another splits up documents or merges them. Other nodes might process meta data or format data. Print processing, tiled rendering or the classification of data streams are further examples of potential nodes. Even simple processes such as packing and unpacking of data in archives take place in nodes.
This sequence does not prescribe that every node has exactly one predecessor and one
successor. For example, there is a pre-defined MultiplexerNode that duplicates data streams
and relays them to various succeeding nodes. On the other hand, a DemultiplexerNode
has several preceding nodes and passes all incoming data streams to just one successor.
The only condition for the configuration of the workflow is that there must not be any
cycles in the arrangement of the nodes.