In vergangenen Versionen der jadice document platform wurde zum Einlesen von Dokumenten die Loader API verwendet. Mit der neuen Generation wird sie durch die Reader API ersetzt, die in zwei Ausprägungen existiert: Einerseits als gewöhnliche Schnittstelle und andererseits mit Methodensignaturen im Stil einer Fluent API. Letztere ist für die Mehrzahl aller Anwendungsfälle besser geeignet und einfacher in der Handhabung und Lesbarkeit.
Das Lesen von Dokumenten mit Hilfe der neuen Fluent Reader API geschieht prinzipiell in drei Schritten:
Erzeugen eines
ReadConfigurerKonfiguration der zu lesenden Dokumentstrukturen (
Documents)Einlesen der Dokumentdaten
Auf diese Weise erzeugte Dokumente stehen zur weiteren Verarbeitung und insbesondere für die Anzeige zur Verfügung. Die folgenden Abschnitte gehen auf die einzelnen Schritte etwas detaillierter ein.
Schritt 1: Erzeugen eines ReadConfigurer
Um Dokumentdaten einzulesen muss zunächst eine Instanz von ReadConfigurer erzeugt
(und konfiguriert) werden. Es existieren dafür zwei unterschiedliche Varianten, die den
Lesevorgang entweder synchron oder asynchron durchführen. Erzeugt werden die
Konfigurationen durch statische Methodenaufrufe der Klasse Read:
SyncReadConfigurer conf = Read.synchronously();
oder:
AsyncReadConfigurer conf = Read.asynchronously();
In den pre jadice 5 Versionen arbeitete der Ladevorgang standardmäßig asynchron.
Dies führte häufig zu der fehlerhaften Annahme, dass nach dem Aufruf
Loader.loadDocument(...)
das Dokument bereits vollständig geladen vorliegt. Die Fluent API
schafft hier mehr Klarheit. Die bewusste Entscheidung, welche Art des ReadConfigurer
verwendet werden soll, vermeidet Missverständnisse und daraus resultierende
Bedienungsfehler.
Schritt 2: Konfiguration der zu lesenden Dokumentstrukturen (Documents)
Nachdem die Erzeugung des ReadConfigurer abgeschlossen ist, kann dessen weitere
Parametrisierung erfolgen. Der ReadConfigurer arbeitet mit Instanzen der Klasse
ReadConfiguration zusammen, die spezifizieren, wie Dokumente aus zugrundeliegenden
Datenquellen zusammengesetzt werden sollen.
Falls zur Parametrisierung direkt die Methoden des ReadConfigurer benutzt werden,
geschieht diese Zusammenarbeit implizit. Oft ist es jedoch sinnvoll, eine eigene
Implementation der ReadConfiguration bereitzustellen. Dies ist insbesondere
interessant, wenn es sich um komplexe Zusammensetzungen handelt oder die Konfiguration
wiederverwendbar sein soll. Unabhängig davon, auf welchem Weg die Konfiguration
vorgenommen wird, sehen die Methodenaufrufe ähnlich aus.
Zum Einstieg zunächst ein einfaches Beispiel ohne spezielle ReadConfiguration. Es
werden darin ein InputStream und eine asynchroner
ReadConfigurer bereitgestellt. Letzterer wird dann angewiesen, aus den Inhalten des
InputStreams ein Dokument zu erstellen.
final InputStream inputStream = [...] AsyncReadConfigurer conf = Read.asynchronously(); conf.newDocument().append(inputStream); conf.execute();
Der abschließende execute-Aufruf beendet die
Konfigurationschritte und startet den Ladevorgang. Sollen mehrere Dokumente
hintereinander geladen werden, kann dies durch weitere append
Aufrufe umgesetzt werden.
final InputStream inputStream1 = [...] final InputStream inputStream2 = [...] AsyncReadConfigurer conf = Read.asynchronously(); conf.newDocument().append(inputStream1).append(inputStream2); conf.execute();
Komplexere Lesevorgänge mit ReadConfiguration und TaskBuilder
Für zusammengesetzte Ladevorgänge ist die Verwendung einer ReadConfiguration
sinnvoll. Das vorhergehende Beispiel würde dann folgendermaßen umgesetzt werden, wobei
hier der Einfachheit halber eine anonyme Klasse verwendet wird.
final InputStream inputStream1 = [...]
final InputStream inputStream2 = [...]
AsyncReadConfigurer conf = Read.asynchronously();
conf.add(new ReadConfiguration() {
@Override
protected void doConfigure() {
newDocument().append(inputStream1).append(inputStream2);
}
});
conf.execute();Obwohl diese Variante zunächst in einer größeren Anzahl Codezeilen resultiert, bietet sie doch einen entscheidenden Vorteil: Sie erlaubt es, regelmäßig wiederkehrende Fälle in einer dedizierten Klasse abzulegen. Typische Anwendungsszenarien sind zusammengesetzes Laden von verschiedenen Datenquellen in ein Dokument oder Ladevorgänge die spezielle Schritte, wie die Anmeldung an ein Backend-System, erfordern.
Im Rahmen unseres Beispiels nehmen wir an, dass für Lesevorgänge auf dem Repository
eine ID notwendig ist, auf deren Basis der InputStream erzeugt
werden kann.
final AsyncReadConfigurer conf = Read.asynchronously(); conf.add(new RepositoryReadConfig()); conf.execute(); [...] // ReadConfiguration als statische innere Klasse public static class RepositoryReadConfig extends ReadConfiguration { @Override protected void doConfigure() { newDocument().append(getInputStreamForID(performRepositoryMagicToGetId())); } private InputStream getInputStreamForID(String id) { // do magic repository reading and return Stream } private String performRepositoryMagicToGetId(){ // do really, really magic stuff ... } }
Zu ihrer vollen Geltung kommt die Eleganz der Fluent Reader
API dort, wo es notwendig ist, komplexere
Dokumentstrukturen aus verschiedenen Datenströmen zu aggregieren. Ein typischer
Anwendungsfall hierfür ist das Laden eines Dokuments mit zugehörigen Annotationen aus
zwei separaten Datenströmen. Da jede Page in der jadice document platform konzeptuell
aus mehreren Ebenen (DocumentLayers) aufgebaut ist, bedarf es einer Möglichkeit,
Inhalte gezielt in eine Ebene zu laden.
Für diesen erweiterten Anwendungsfall ist aus technischen Gründen die Hilfe eines
TaskBuilders notwendig, der es erlaubt Konfigurationsschritte weiter zu
konkretisieren. Die im Beispiel erweiterte Klasse ReadConfiguration stellt mit
protected TaskBuilder task(InputStream source) {...}einen solchen zur Verfügung. Sollen mehrere Streams auf eine Seite geladen werden,
müssen diese zudem miteinander gruppiert werden. Dies geschieht durch einen Aufruf von
appendGroup(). Streams, die der Gruppe angehängt werden sollen,
können durch add(...) hinzugefügt werden. Mit einem Aufruf von
append(...) oder appendGroup() wird hingegen
eine neue Seite begonnen.
Die Beispielklasse RepositoryReadConfig sieht mit den
Änderungen folgendermaßen aus:
// ReadConfiguration als statische innere Klasse public static class RepositoryReadConfig extends ReadConfiguration { @Override protected void doConfigure() { String id = performRepositoryMagicToGetId(); newDocument() .appendGroup() .add(task(getContentInputStream(id))) .add(task(getAnnoInputStream(id)).mapDefaultLayer().toAnnotationsLayer()); } private InputStream getContentInputStream(String id) { // ... } private InputStream getAnnoInputStream(String id) { // ... } private String performRepositoryMagicToGetId(){ // do really, really magic stuff ... } }
Die Konfiguration kann auch mehr als zwei Ebenen enthalten. Dies zeigt das folgende Beispiel mit Quelltext und Screenshot:
// ReadConfiguration als statische innere Klasse public static class RepositoryReadConfig extends ReadConfiguration { @Override protected void doConfigure() { String id = performRepositoryMagicToGetId(); newDocument() .appendGroup() .add(task(getBackgroundInputStream(id)).mapDefaultLayer().toBackgroundLayer()) .add(task(getContentInputStream(id))) .add(task(getWatermarkInputStream(id)).mapDefaultLayer().toFormLayer()) .add(task(getAnnoInputStream(id)).mapDefaultLayer().toAnnotationsLayer()); } private InputStream getAnnoInputStream(String id) { // ... } private InputStream getWatermarkInputStream(String id) { // ... } private InputStream getContentInputStream(String id) { // ... } private InputStream getBackgroundInputStream(String id) { // ... } private String performRepositoryMagicToGetId(){ // do really, really magic stuff ... } }
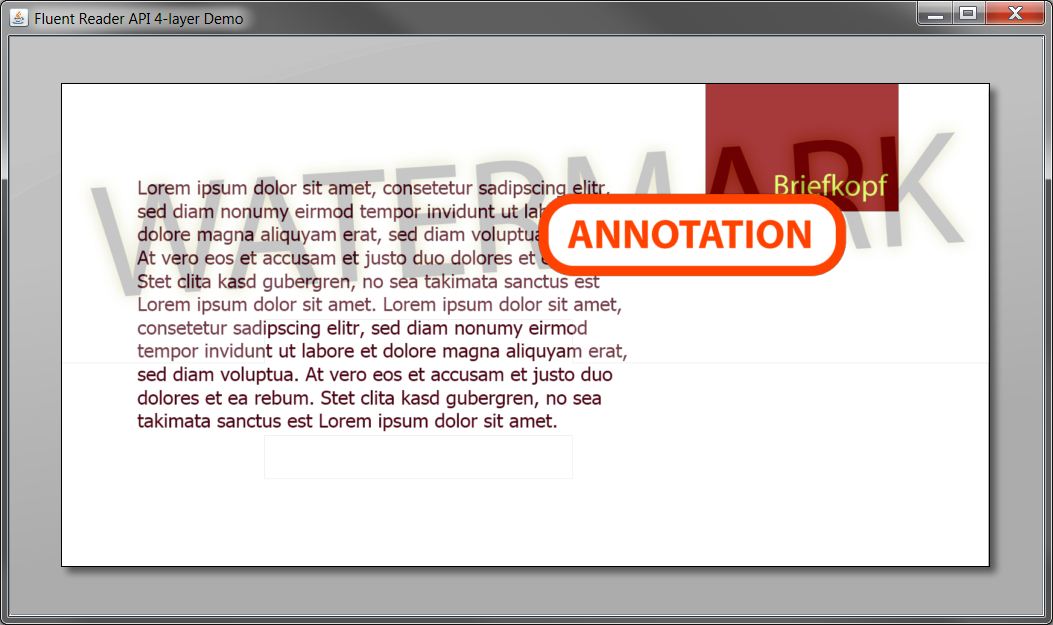
Nachdem die Konfiguration vorgenommen ist, kann der tatsächliche Lesevorgang ausgelöst werden. Dies geschieht durch Aufruf der execute() Methode auf dem ReadConfigurer.
Ab diesem Zeitpunkt ist es möglich, das erzeugte Dokument vom ReadConfigurer zu
erfragen und dann natürlich auch anzuzeigen.